前言
我們來做 How Google does Machine Learning 的第二個lab~
這次鐵人賽的30天中,我目前所寫文章的所有課程目錄如下:
Course - How Google does Machine Learning
第五章節的課程地圖:(紅字標記為本篇文章中會介紹到的章節)
- Python notebooks in the cloud
- Module Introduction
- Cloud Datalab
- Cloud Datalab
- Demo: Cloud Datalab
- Development process
- Demo of rehosting Cloud Datalab
- Working with managed services
- Computation and storage
- Lab: Rent-a-VM
- Intro to Qwiklabs
- Intro to Renting-VM Lab
- Lab: Rent-a-VM to process earthquake data
- Lab debrief
- Cloud Shell
- Third wave of cloud
- Third Wave of Cloud: Fully-Managed Services
- Third Wave of Cloud: Serverless Data Analysis
- Third Wave of Cloud: BigQuery and Cloud Datalab
Datalab and BigQueryLab Intro: Analyzing data using Datalab and BigQueryLab: Analyzing data using Datalab and BigQueryLab Debrief: Analyzing Data using Datalab and BigQuery
- Machine Learning with Sara Robinson
- ML, not rules
- Pre-trained ML APIs
- Vision API in action
- Video intelligence API
- Cloud Speech API
- Translation and NL
- Lab: Machine Learning APIs
- Lab: Pretrained ML APIs Intro
- Lab: Invoking Machine Learning APIs
- Lab Solution
Lab: Analyzing Data using Datalab and BigQuery
課程地圖
- Python notebooks in the cloud
- Datalab and BigQuery
- Lab Intro: Analyzing data using Datalab and BigQuery
- Lab: Analyzing data using Datalab and BigQuery
- Lab Debrief: Analyzing Data using Datalab and BigQuery
- Datalab and BigQuery
在這個lab中,我們將使用BigQuery去分析7000萬行左右的資料,
並將結果以幾十行的Pandas DataFrame輸出。
再來我們可以直接使用Pandas DataFrame的結果作資料視覺化。
註:
BigQuery= 大量資料分析工具
在這裡我們只需要數秒鐘就可以創建圖形,這是使用其他方法可能做不到的。
然而,在互動式的開發流程中我們會很需要即時的分析,
對於大量資料的處理來說,這樣的速度是重要的,
你可能會想說,那就不要處理這麼多資料就好了啊?
問題是,如果我們處理的資料量小,這就不會是個好的 machine learning practice的範例了。
統計方法 與 machine learning 的關鍵差別?
另外一件事情是,我們想順便討論 統計方法 與 machine learning 的關鍵差別,
關於我們如何處理離群值。
在統計方法中,我們會傾向移除離群值。
但在 machine learning 中,離群值也會是我們學習的內容。
而且如果要學習離群值,我們也必須要有足夠的離群值資料,
我們還需要確保這些離群值在資料集中被分配,做好管理完整dataset的工作就顯得重要。
在這個實驗中我們提供了BigQuery能幫助你管理大量的dataset,
然後能替我們帶來更習慣的資料結構(例如:Pandas),
我們也可以使用python的繪圖工具製圖,就是我們這個lab的主要內容。
part 0 : (事前準備) 開啟 GCP console
請先參考 【Day 9】- 每次在google雲端上開始lab前都要的事前準備與注意事項 的內容,完成到運行中階段。
part 1 : (建立機器) 建立 Datalab VM
Step 0 : 打開 Cloud Shell
如果不清楚 Cloud Shell 如何開啟,請參考 【Day 11】- Cloud Shell 的介紹與 google雲的三代變化, 使用ML與一般演算法的比較與優勢
Step 1 : 首先我們要先知道我們的 compute zones 在哪,我們可以透過以下指令知道我們所有的 compute zones 位置,我們會在其中一個 compute zones 運行我們的 Datalab。
gcloud compute zones list
註:影片中的範例使用的是 U.S. Central。
Step 2 : 我們透過以下指令創建我們的 datalab VM。
datalab create mydatalabvm --zone <ZONE>
- 依照影片中的範例,我們必須填入:
datalab create mydatalabvm –zone us-central1-b
創建過程約需稍等五分鐘。
Step 3 : 創建過程中,可能會碰到如紅框處的問題(詢問ssh passphrase)。
第一個問題回答 “Y”
第二三個問題直接按 “Enter” return即可。
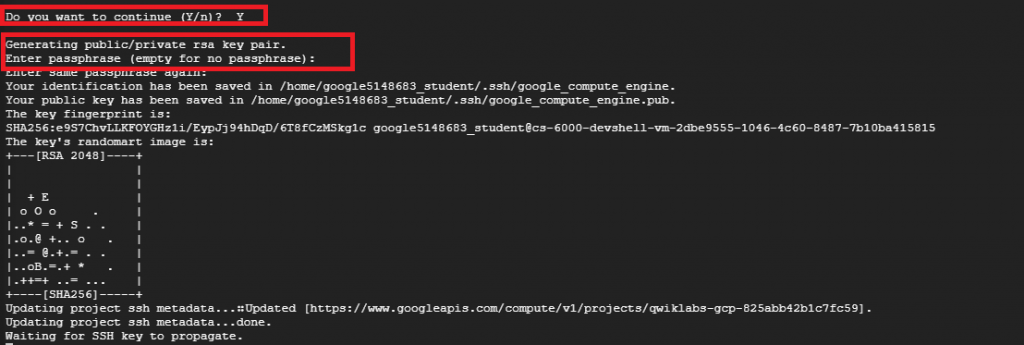
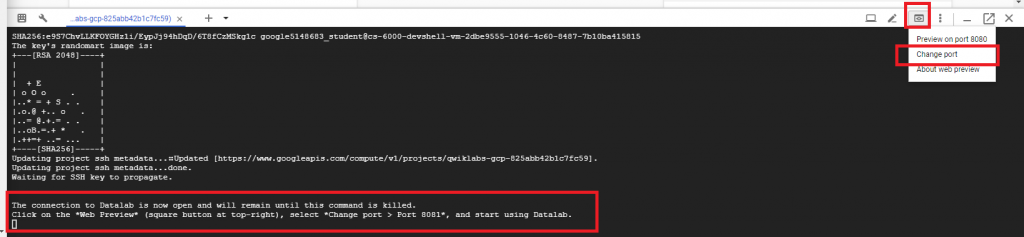
Step 4 : 直到看到下方處出現請你開啟 “Web Preview” 的訊息才算建立完成,這時按 Cloud Shell 的右上角,
點選 Change Port,並更換我們的 port 至 8081,完成後點選 CHANGE AND PREVIEW。
part 2 : (啟用API) 開啟 Cloud Source Repositories API
Step 1 : 確定 Cloud Source Repositories API 是被開啟的:
點選一下網址,記得要切換至"Qwiklabs所提供的帳號“開啟API應用。
https://console.cloud.google.com/apis/library/sourcerepo.googleapis.com/?q=Repositories
part 3 : (分析資料) 使用 BigQuery 分析資料
Step 1 : 我們先從 Google Console開啟 BigQuery (紅框處),一樣透過”Qwiklabs所提供的帳號密碼“來進行登入
稍微確認一下 Project名稱是否與 Qwiklabs的名稱相同。
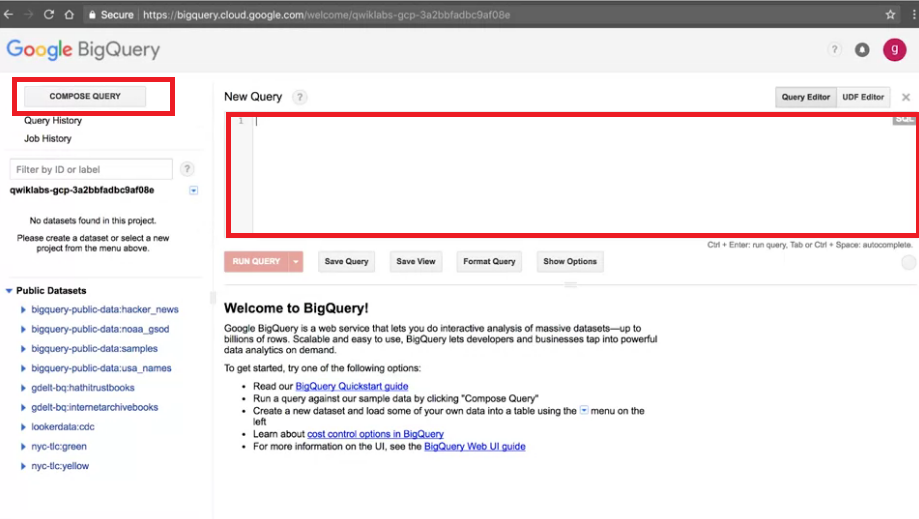
Step 2 : 我們可以按 COMPOSE QUERY 開始執行QUERY的視窗。(紅框處,實際介面可能稍有不同。)
Step 3 : 在執行QUERY的視窗輸入以下指令,並執行。
#standardSQL SELECT departure_delay, COUNT(1) AS num_flights, APPROX_QUANTILES(arrival_delay, 5) AS arrival_delay_quantiles FROM `bigquery-samples.airline_ontime_data.flights` GROUP BY departure_delay HAVING num_flights > 100 ORDER BY departure_delay ASC
這是 standard SQL的語法。
但同樣的我們也可以不使用standard SQL的語法,我們點選 Show Options。
我們可以看到更多選項,並取消勾選 Legacy SQL。
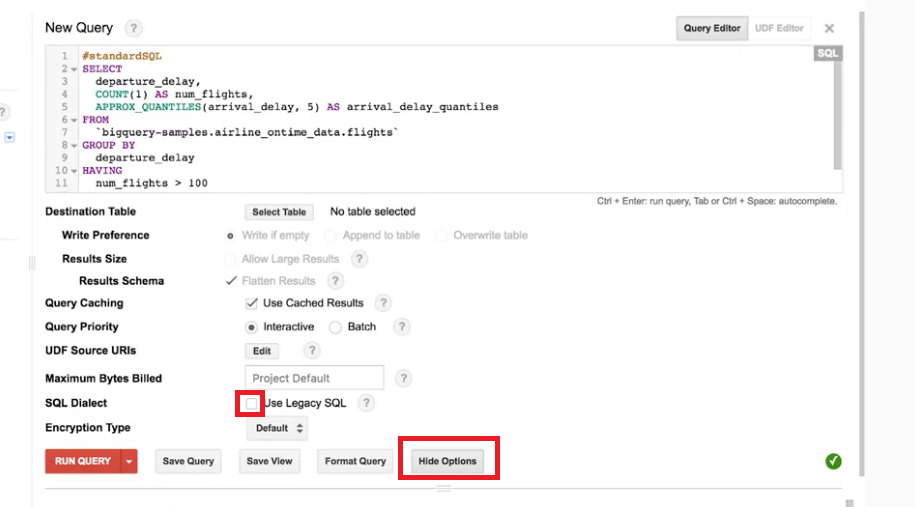
我們在稍微注意一下語法中From的部分,我們會發現這個dataset來自 bigquery-samples 中的 airline_ontime_data,而 table 的名字是 flights。
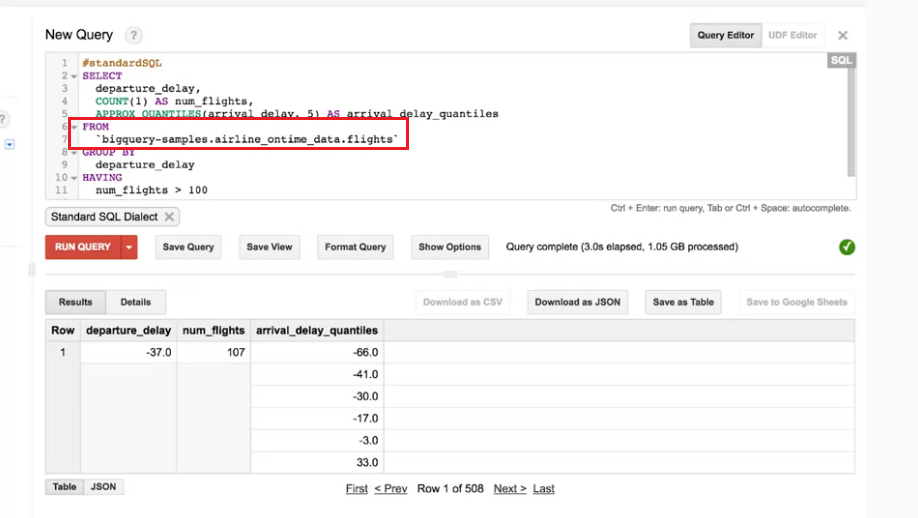
Step 4 : (練習題) 試從以下的結果判斷:35分前離開的班機延遲抵達時間的中位數是多少?
說明:我們先看Step 3中例子的圖來解釋,
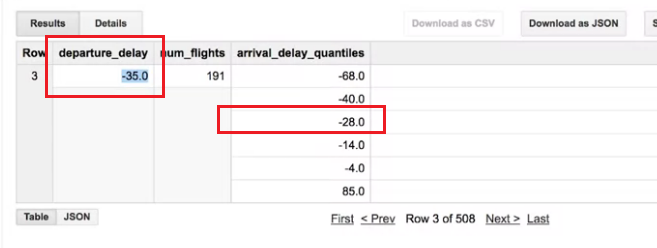
departure_dalay:表示班機離開的時間,-37也表示37分鐘前離開。
我們可以看到在num_flights中找到107個班機35分前離開,這些格子細分成五格表示五個級距,
-66 表示80%飛機抵達時提前66分鐘或更早,-41~-66 表示 60%~80% 飛機在這個區間抵達。
解答: 所以如果我們問你35分前離開的班機延遲抵達時間的中位數是多少? 答案就是提早28分鐘到達。
Step 5 : (練習題2) 試著寫一個Query找出:擁有最大的航班數的airport pair (departure and arrival airport)。(指的是兩機場間的航班數最多)
參考解答:
#standardSQL SELECT departure_airport, arrival_airport, COUNT(1) AS num_flights FROM `bigquery-samples.airline_ontime_data.flights` GROUP BY departure_airport, arrival_airport ORDER BY num_flights DESC LIMIT 10
解釋:
- 我們先用
GROUP BY,將 departure_airport, arrival_airport選定 - 並在 departure_airport, arrival_airport 用
COUNT(1) AS num_flights,計算兩機場的總航班數 ORDER BY可以幫助我們排序,num_flights DESC,表示 num_flights的降序排列,因為透過降序我們就可以找到最多數量的位於最上方。LIMIT限制10,因為我們只要找最多,所以也不需要顯示太多結果。
結果:LAX(起飛) 與 SAN(降落) 一共有 133394 航班數。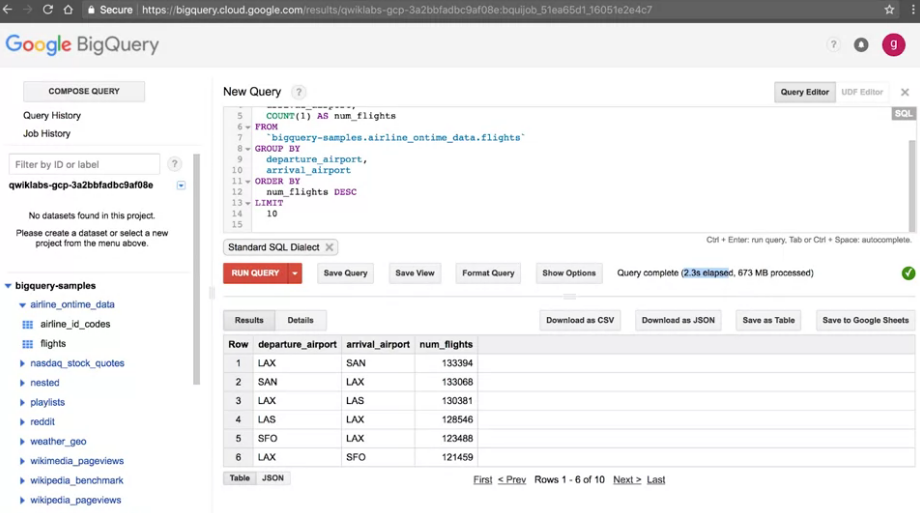
我們約花2.3秒搜尋了7000萬筆的資料。看似不可思議,但其實這就是數以千計的電腦一起搜尋的結果。
這就是我們所說的 run at scale,也是雲端運行服務,我們不必自己負擔運算過程,達到serverless的效果。
part 4 : (視覺化結果) 使用 Datalab 建立視覺化結果
BigQuery分析東西很方便,但他沒辦法幫我們視覺化的分析結果,
我們現在用Datalab來幫助我們建立視覺化結果。
Step 0 : 接下來會直接使用 Cloud Datalab 跑 pyhton 程式
如果不清楚 Cloud Datalab 的基本指令與運作,請先複習 【Day 8】- 先來初步認識一下google雲端上執行 python notebook (Cloud Datalab) 的環境
Step 1 : 我們回到 part 1 所開啟的 Datalab,按左上角開啟一個新的 notebook。
Step 2 : 我們在第一格cell中貼上這段code,這段code是呼叫BigQuery幫我們執行的,我們只是透過API串接過來使Datalab能夠使用。
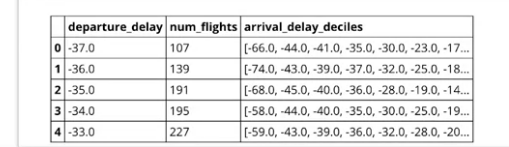
query=""" SELECT departure_delay, COUNT(1) AS num_flights, APPROX_QUANTILES(arrival_delay, 10) AS arrival_delay_deciles FROM `bigquery-samples.airline_ontime_data.flights` GROUP BY departure_delay HAVING num_flights > 100 ORDER BY departure_delay ASC """ import google.datalab.bigquery as bq df = bq.Query(query).execute().result().to_dataframe() df.head()
而在code的最後幾行.to_dataframe(),將我們回傳的資料轉成 Pandas Dataframes。
我們也可以透過.head(),從結果中先偷看前幾行的內容。
也正如同我們之前在BigQuery所執行的一樣,有departure_delay, number of flights…,
但這例子中我們有10分位數,因為我們在APPROX_QUANTILES(arrival_delay, 10)中下了數字10,所以我們可以得到10個數字。
Step 3 : 我們在第二格cell中貼上這段code。
import pandas as pd percentiles = df['arrival_delay_deciles'].apply(pd.Series) percentiles = percentiles.rename(columns = lambda x : str(x*10) + "%") df = pd.concat([df['departure_delay'], percentiles], axis=1) df.head()
這段code能幫助我們把十分位數的部分整個分開整理清楚,如下圖。
分開的原因與下步驟的製圖有關係。

Step 4 : 我們在第三格cell中貼上這段code。
without_extremes = df.drop(['0%', '100%'], 1) without_extremes.plot(x='departure_delay', xlim=(-30,50), ylim=(-50,50));
在第一行.drop([‘0%’, ‘100%’], 1),我們先將0%, 100%的結果移除,不畫入圖中,
我們在最後的結果只使用10%~90%的資料。
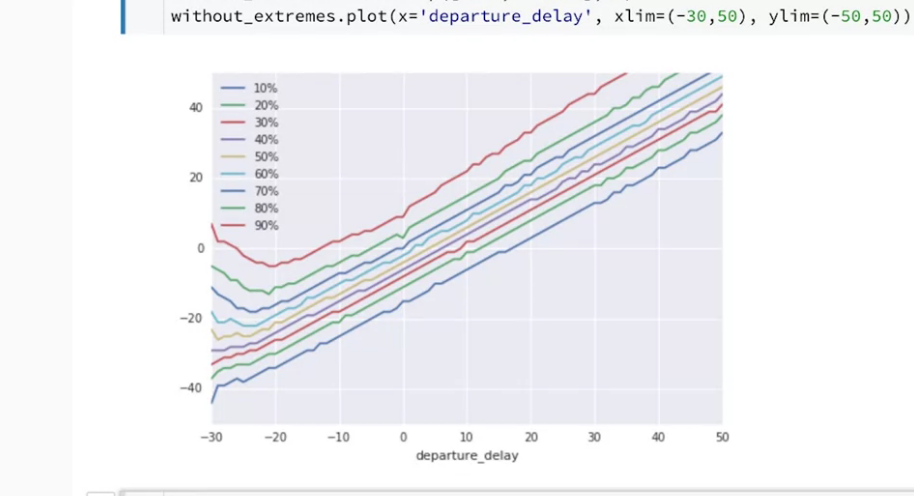
我們試著閱讀這張圖,departure_delay如果是10,表示10分鐘delay,
我們可以看見10%的班機仍然可以提前到達,但90%的班機會晚21分鐘以上到達。
另外一方面中位數(50%)的 departure_delay 所對應到的 arrival_delay 約提早3~4分鐘。
我們看結果會發現,除了一些 -20 以下的結果,這些結果的呈現滿線性的,
我們的結果只要在中間不在邊緣,基本上可以做一個縣性模型。
現在我們可以回來想,我們分析了多大的資料才能得到這樣的結果,
這樣的insight,正是一種很難透過其他方式能獲得的結果。
本文同步發佈在: 第 11 屆 iT 邦幫忙鐵人賽
【Day 13】 Google ML - Lab 2 - Analyzing Data using Datalab and BigQuery - 使用 BigQuery與Datalab視覺化分析資料
參考資料
coursera - How Google does Machine Learning 課程
若圖片有版權問題請告知我,我會將圖撤掉